Study Notes
Study Notes on Stochastic Differential Equations
Study Notes
Study Notes on Stochastic Optimal Control
Technical Tutorials
BibTeX .bib and .bbl
Technical Tutorials
Obsidian Plugin Math Booster
Study Notes
Study Notes on Diffusion
Technical Tutorials
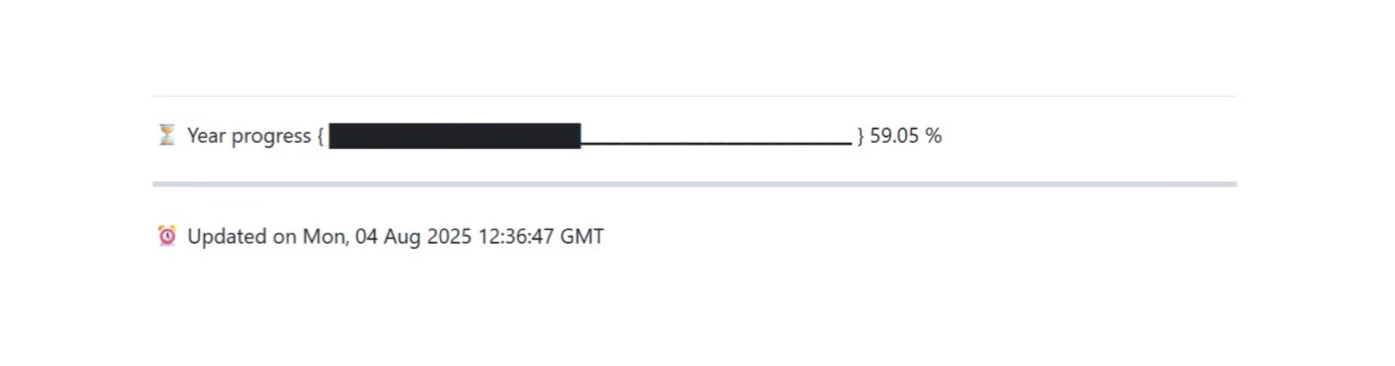
Add a Year Progress to Your GitHub Profile Page
Technical Tutorials
Git and SSH
Study Notes
Study Notes on Optimal Transport
Coding Knowledge
Latex Math Symbols CheatSheet
Study Notes
Study Notes on DataBase
1
2
3